

Dominik Vereno verschafft sich den Durchblick im Code.
Bei seinem Bachelor-Projekt zur Testautomatisierung hat sich Dominik Vereno an Millionen Zeilen von Code abgearbeitet. Der Student der FH Salzburg ist mit einem Nebenjob im Kundensupport in die Porsche Informatik eingestiegen und hat mittlerweile den Sprung zum Software-Entwickler gemacht. Wie sein wissenschaftliches Projekt gelaufen ist und was die IT mit Klettern zu tun hat, erklärt er uns im Interview:
Warum hast du dich für das Thema deines Praktikums entschieden? Wie ist der Entschluss in dir gereift, gerade dieses eine Projekt in dieser Firma umzusetzen?
Ich habe schon nach der Zeit im Support über das Study-Work-Support-Programm angefangen, in der Abteilung „CROSS 2“ mitzuarbeiten. Da war es naheliegend, auch mein Bachelor-Praktikum hier zu absolvieren. Der erste Teil des Projektes erfolgte in Abstimmung mit dem Abteilungsleiter. Wir haben verschiedene Themen und Problematiken besprochen. Die Optimierung der Ausführdauer von Unit-Tests war für mich deswegen spannend, weil es viele messbare Aspekte beinhaltet. Unit-Tests sind ein großer Teil der Qualitätssicherung. Besonders durch Zeitmessung und statistische Auswertungen von Messergebnissen kann man das Thema sehr gut in Form einer wissenschaftlichen Arbeit aufbereiten.
Wie frei warst du in der Gestaltung deines Projekts?
Beim Abwägen verschiedener Möglichkeiten hat sich das eigentliche Projekt dann herauskristallisiert. Der Ausgangspunkt war eine relativ allgemeine Problemstellung. Die Aufgabe lautete nicht, ein bestimmtes Problem auf eine bestimmte Weise zu lösen, sondern meinen eigenen Weg zur Lösung des Problems zu finden. Die Umsetzung war komplett mir überlassen.

Dominik Vereno im Interview mit Blogautor Wolfgang Brandner.
Was genau war nun die konkrete Problemstellung, und wie war dein Ansatz?
Konkret benötigte die Ausführung der Unit-Tests in der CROSS-2-Entwicklung zu viel Zeit. Für Continuous Integration ist es wichtig, dass die Verification Builds, die erfolgen, wenn eine Änderung eingecheckt wird, schnell laufen. Dadurch erhalten die Entwickler rasches Feedback. Die ursprüngliche Annahme lautete, dass die Datenbankverbindungen, die in den Unit-Tests aufgebaut werden, große Verzögerungen verursachen. Ich habe schließlich herausgefunden, dass der Aufbau dieser Verbindungen zwar einen kleinen Unterschied macht, aber nicht die einzige Ursache für die Verzögerungen ist. Ein Großteil der Ausführungsdauer ist eigentlich Overhead, und nur ein geringer Teil davon wird für das Ausführen von Testmethoden verwendet. Ein simpler Ansatz wäre daher, dafür zu sorgen, dass der Overhead nur einmal und nicht für alle Subsysteme separat anfällt.
Worin besteht jetzt genau der Gewinn für uns?
Der Gewinn besteht darin, dass die Entwickler schnell Feedback erhalten, ob alles richtig gebaut wird und ob Unit-Tests brechen, wenn man eine Änderung vornimmt. Durch die starke Reduktion der Ausführungsdauer der Unit-Tests kann man dieses Feedback deutlich beschleunigen. Das war nun der eine Teil des Bachelor-Projekts.
Und der zweite Teil?
Weil sich für das Problem relativ schnell eine Lösung herauskristallisiert hat, war der Vorschlag, noch ein weiteres Projekt anzuschließen. Dieses wurde ursprünglich „Social Code Analysis“ getauft. Dabei werden nicht nur statische Metriken über den Code, sondern auch die Änderungsgeschichte berücksichtigt. Das Grundkonzept ist, die Komplexität des Codes zu betrachten. Welcher Code ist komplex, welcher Code hat sich häufig geändert? Die Wahrscheinlichkeit ist nämlich groß, dass im Code, der sich häufig ändert, eher Fehler enthalten sind als in jenem Code, der schon seit 10 Jahren unverändert in der Codebasis ist. Außerdem: Welche dieser komplexen Klassen, die sich auch häufig ändern, hat eine schlechte Testabdeckung? Bei welchen Klassen und Codesegmenten müsste man dringend die Testabdeckung verbessern? Wo erreicht man dadurch den größten Nutzen für die Fehlererkennung? Das ist auch das Alleinstellungsmerkmal meiner Arbeit, das hebt sie von anderen ab.
„Social Code Analysis“ hört sich an, als würde da spezielles Augenmerk auf die menschliche Komponente gelegt?
Ja, genau. Wenn man sich nur den Code ansieht, kann man Komplexität, Länge oder Verzweigungen beurteilen. Durch „Social Code Analysis“ kann man beurteilen, wie, wie oft und von wie vielen verschiedenen Entwicklern der Code verändert wurde und wie diese Veränderungen zeitlich zusammenhängen. Wenn beispielsweise ein Entwickler in kurzer Zeit an zwei verschiedenen Klassen arbeitet, die eigentlich nicht voneinander abhängen, kann man Zusammenhänge erkennen, die man vielleicht durch statische Beobachtungen nur schwer feststellen könnte.
Was ist der Unterschied zu herkömmlichen automatisierten Testkonzepten?
Besonders in einem großen System kann man damit beurteilen, wo die Verbesserung der Testabdeckung am dringendsten erforderlich wäre, also welche die Problemklassen sind. Es geht darum, zu priorisieren. Ich habe nur wenige wissenschaftliche Artikel gefunden, die Änderungsgeschichte und Änderungshäufigkeit überhaupt berücksichtigen. Insofern ist „Social Code Analysis“ also Neuland.
Hattest du das Gefühl, dass es bei uns in dieser Hinsicht viel zu tun gibt, oder bist du in eine Testlandschaft gekommen, die schon sehr gut bestellt war?
Ich habe Code auf einer Metaebene untersucht und musste nicht durch das Dickicht der automatisierten Tests irren. Natürlich kann die Testabdeckung immer verbessert werden. Bei einem System, das über 15 Jahre gewachsen ist und 12 Millionen Zeilen Code umfasst, ist es für Entwickler selbst entsprechend schwer, den Überblick zu behalten. Wo setzt man da an, wenn man die Testabdeckung verbessern will? Auf einer objektiveren Ebene die Klassen oder Klasseneigenschaften zu quantifizieren, gibt auch jemandem, der sich nicht auskennt, die Möglichkeit, eine gute Einschätzung vorzunehmen.
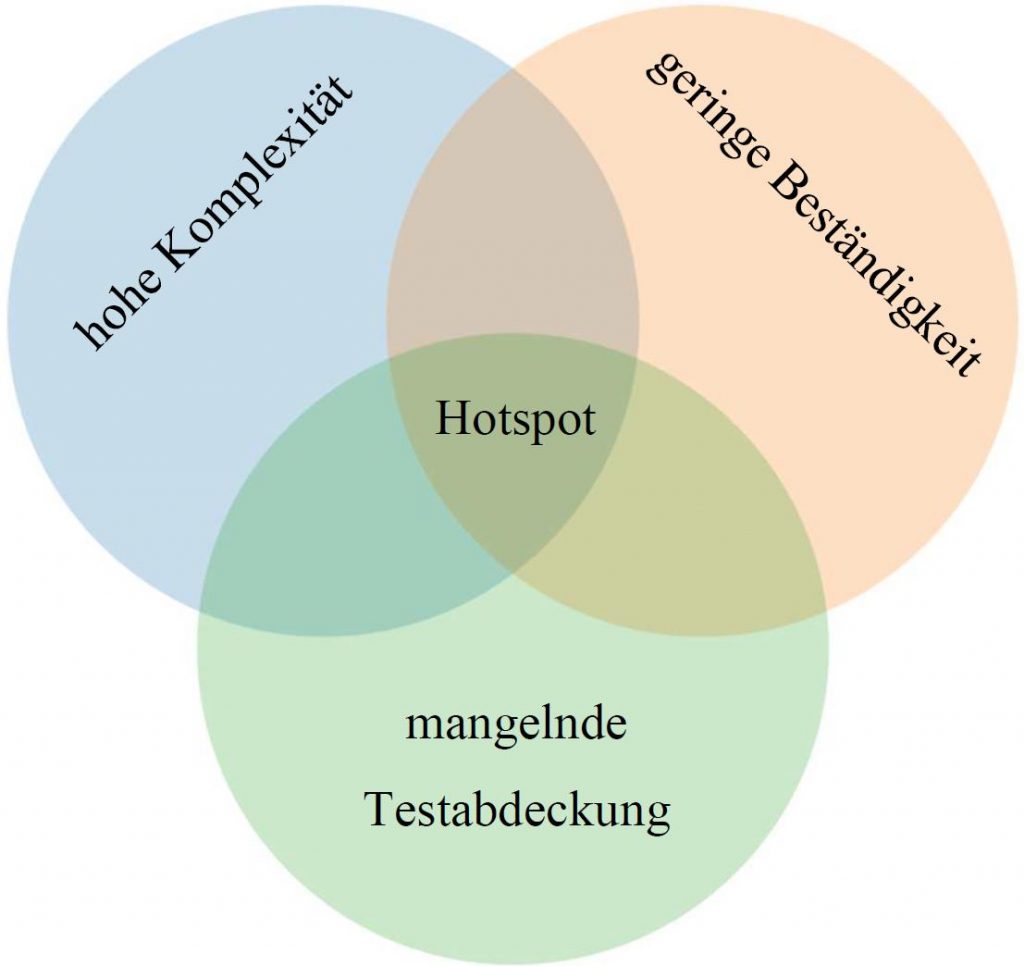
Je komplexer, unbeständiger und seltener getestet, desto größer die Fehlerwahrscheinlichkeit im Code.
Arbeitest du hier bei Porsche Informatik nun das erste Mal mit einem produktiv eingesetzten System?
Ich bin jetzt am Ende des Bachelor-Studiums und habe dadurch natürlich Erfahrung gesammelt, aber noch nie an einem großen Produktionssystem mit einer so umfangreichen Codebasis gearbeitet. Automatisiertes Testen habe ich bei eigenen Projekten und Studienprojekten umgesetzt. Und ich habe mich davor privat viel mit dem Thema beschäftigt.
Du hast dich also mit wissenschaftlichen Ansätzen beschäftigt, und dann triffst du auf ein großes System mit vielen Millionen Zeilen Code. Wie groß war denn da dieser Kulturschock für dich, diese Kluft zwischen akademischer Theorie und tatsächlicher Praxis?
In einem Studium oder einem theoretischen Umfeld wird natürlich viel idealisiert, und die Größenordnung ist eine andere. In einem großen Projekt auf der FH erledigt man sehr viel selbst und arbeitet sehr eng mit Kollegen zusammen. Wenn man dann in eine Abteilung kommt, die schon jahrelang an einem System arbeitet, das dementsprechend groß ist, ist das etwas ganz anderes. Man muss damit zurechtkommen, dass man eigentlich nur einen winzigen Teil des gigantischen Softwaresystems sieht und verstehen kann. Besonders, wenn man davor noch nicht mit größeren, historisch gewachsenen Systemen gearbeitet hat, ist das natürlich ein Kulturschock.
Ist es dir schwergefallen, dich an das anzupassen, was du vorgefunden hast? Ich stelle mir das vor wie einen Kletterer, der nur die Halle kennt und auf einmal vor einem richtigen Berg steht …
Ich bin selbst kein Kletterer, aber ich schätze, in einer Halle ist das Risiko ganz anders, als wenn man jetzt wirklich auf den Berg klettert und die Sicherung viel ernster nehmen muss. Und natürlich ist es auch am Anfang schwer, damit zurechtzukommen. Es gibt unzählige Dateien, von denen man jeweils nur einen winzigen Ausschnitt sieht und dann Zusammenhänge und Funktionsaufrufe in ganz anderen Klassen und in ganz anderen Subsystemen findet, von deren Aufgabe man noch gar keine Ahnung hat. Was natürlich extrem geholfen hat, ist ein Netz an Teamkollegen, die sehr offen gegenüber Fragen sind und die man auch richtig piesacken kann. Trotzdem werden diese Fragen mit extremer Geduld und Hingabe beantwortet.
Kollegen, die dich dann in der Wand absichern …
Genau. Die erfahreneren Kletterer helfen bei der Sicherung und schauen, dass du es auch schaffst. Ich hatte das Gefühl, man wird auf jeden Fall mitgenommen.
Nachdem das jetzt dein erster offizieller Arbeitstag nach dem Praktikum ist, wie ist die Arbeit mit CROSS 2?
Ich habe ja schon davor einen Überblick über Framework-Komponenten und den allgemeinen Aufbau gehabt. Was jetzt kommt, sind sehr viele Aspekte des täglichen Arbeitsablaufes, sei es, wie Aktivitäten verwaltet werden, die Codesicherung, das Testen, das Einchecken. Das ist Neuland und will erlernt werden. Die Arbeit im Praktikum war sehr selbständig, wo ich selber extrem viele Freiheiten hatte und mir sehr viele Wege offenstanden. Ich konnte mich da sehr frei entscheiden. Jetzt bin ich in ein Team eingegliedert, wo man auch seinen Teil leisten und sich anpassen muss.
Wie geht es dann mit dir persönlich weiter?
Im Studium werde ich mich auf die Bereiche Data Science und Robotik spezialisieren, weil das Themen sind, die mich sehr interessieren.
Neben dem Studium zu arbeiten, ist eine Herausforderung. Aber du hast dann auf jeden Fall einen deutlichen Praxisbezug.
Das Angenehme ist, dass ich bei Porsche Informatik die Möglichkeit habe, schon während des Studiums – noch grün hinter den Ohren – viel Praxiserfahrung zu sammeln. Wenn ich mit dem Studium fertig bin, habe ich nicht nur den akademischen, sondern auch einen beruflichen Hintergrund.
